



Content Moderation
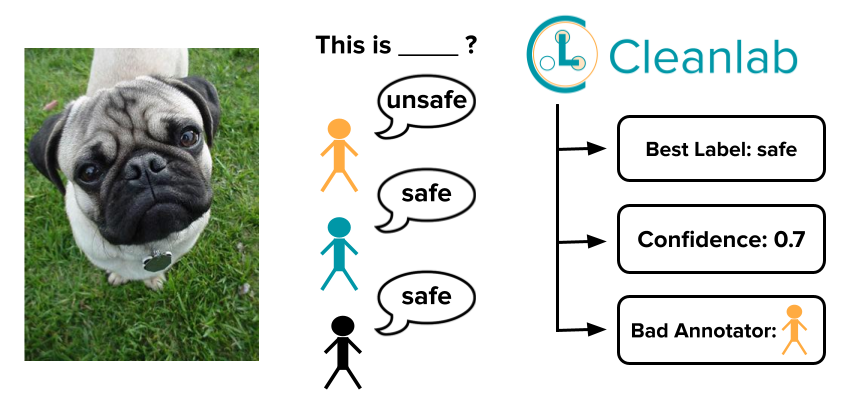
Find labeling errors; Decide when another review is appropriate; Discover good/bad moderators; Deploy robust ML models with 1-click.

Case StudyToxic Language Detection @ VAST-OSINT
VAST-OSINT used Cleanlab to identify incorrect labels to improve toxic language detection models.
I took the sentence-labeled training data and threw it at cleanlab to see how well confident learning could identify the incorrect labels. These results look amazing to me.
If nothing else, this can help identify training data to TOSS if you don't want to automate correction.

HOW CLEANLAB HELPS YOU BETTER MODERATE CONTENT
Related applications

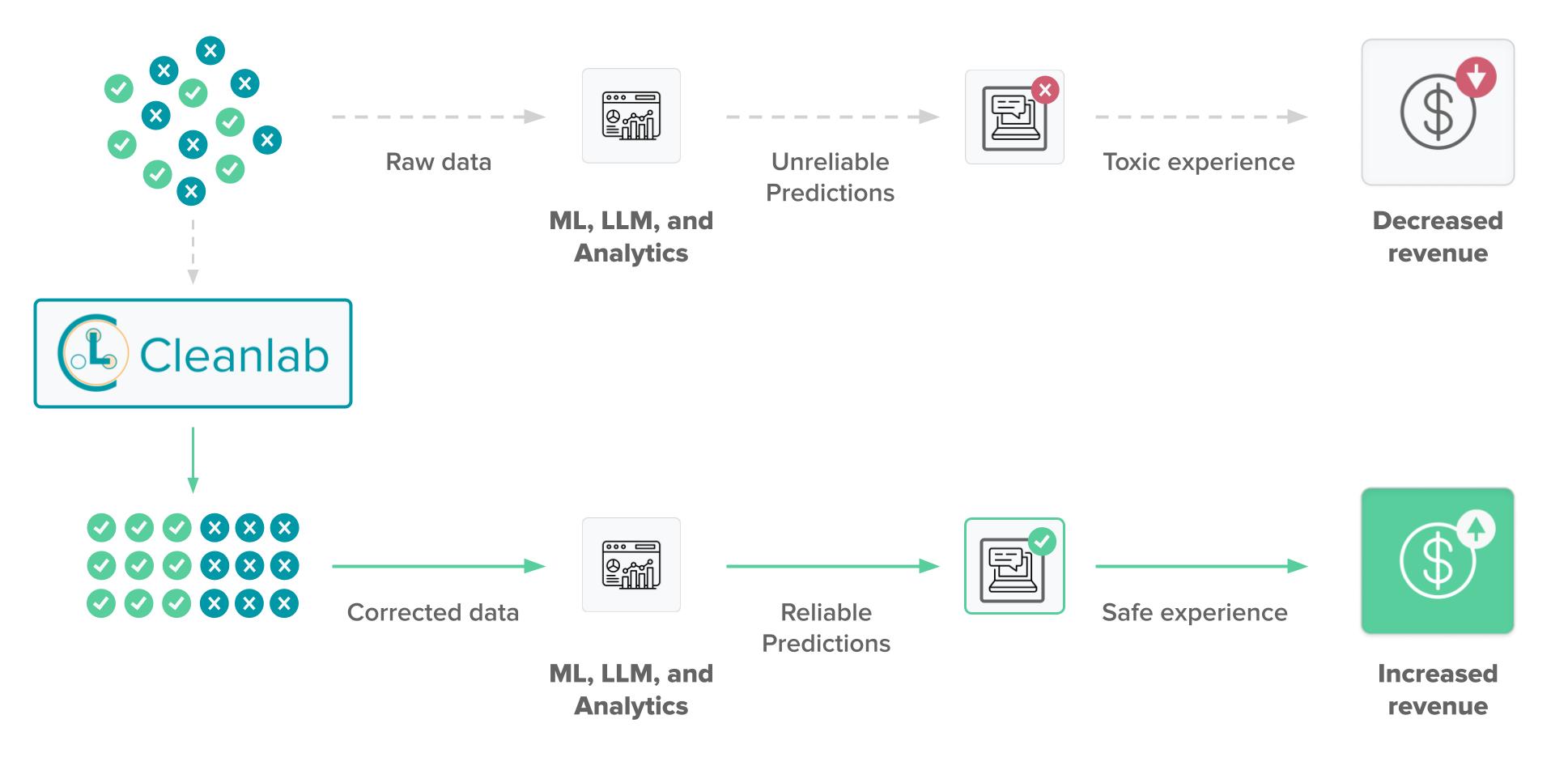
Cleanlab Studio auto-corrects raw data to ensure reliable predictions so you can provide safe user experiences.
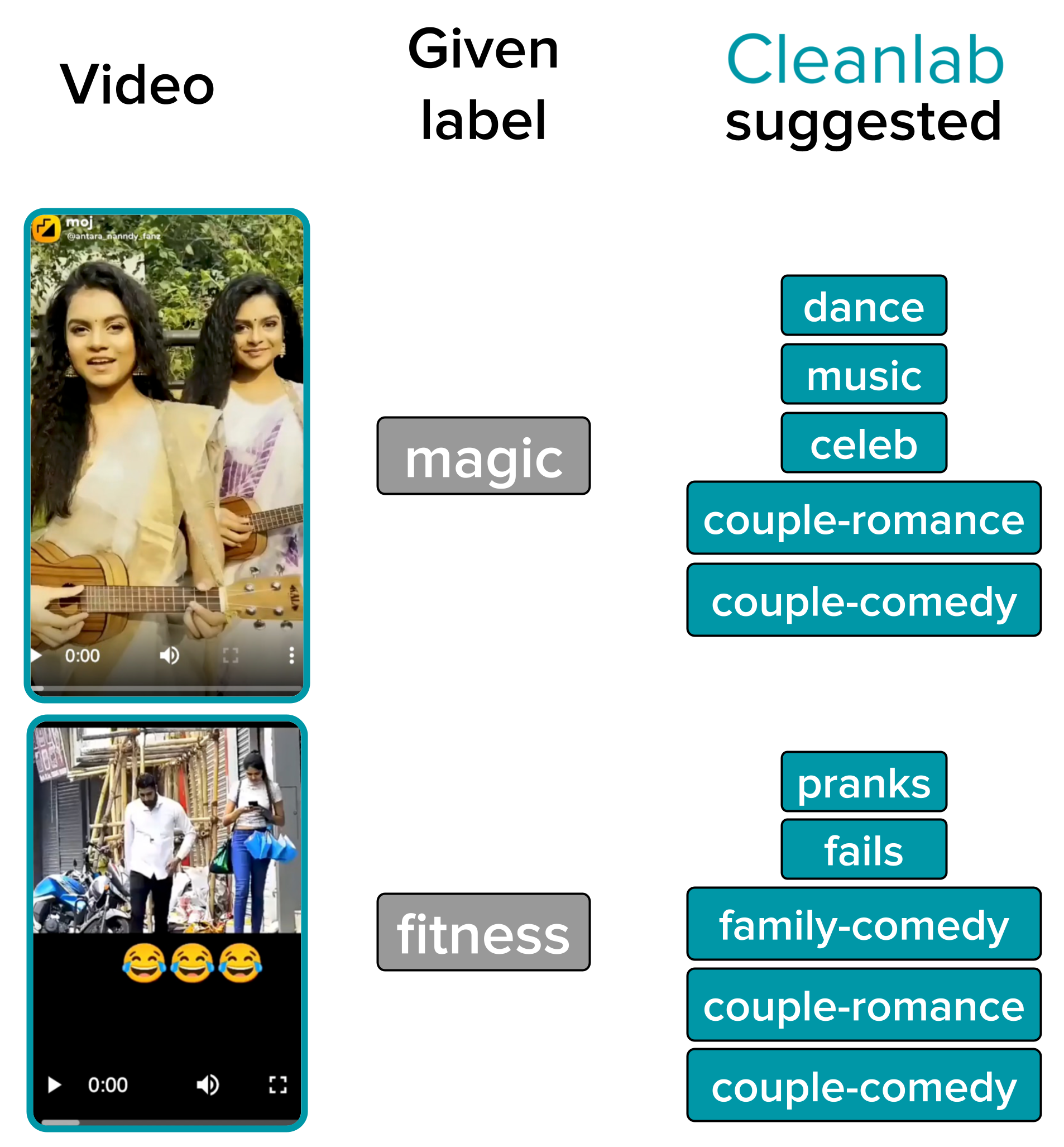
SHARECHAT USES CLEANLAB TO IMPROVE CONTENT CLASSIFICATION
Cleanlab automatically identified an error rate of 3% in the concept categorization process for content in the Moj video-sharing app. Shown are a couple mis-categorized examples that Cleanlab detected in the app.
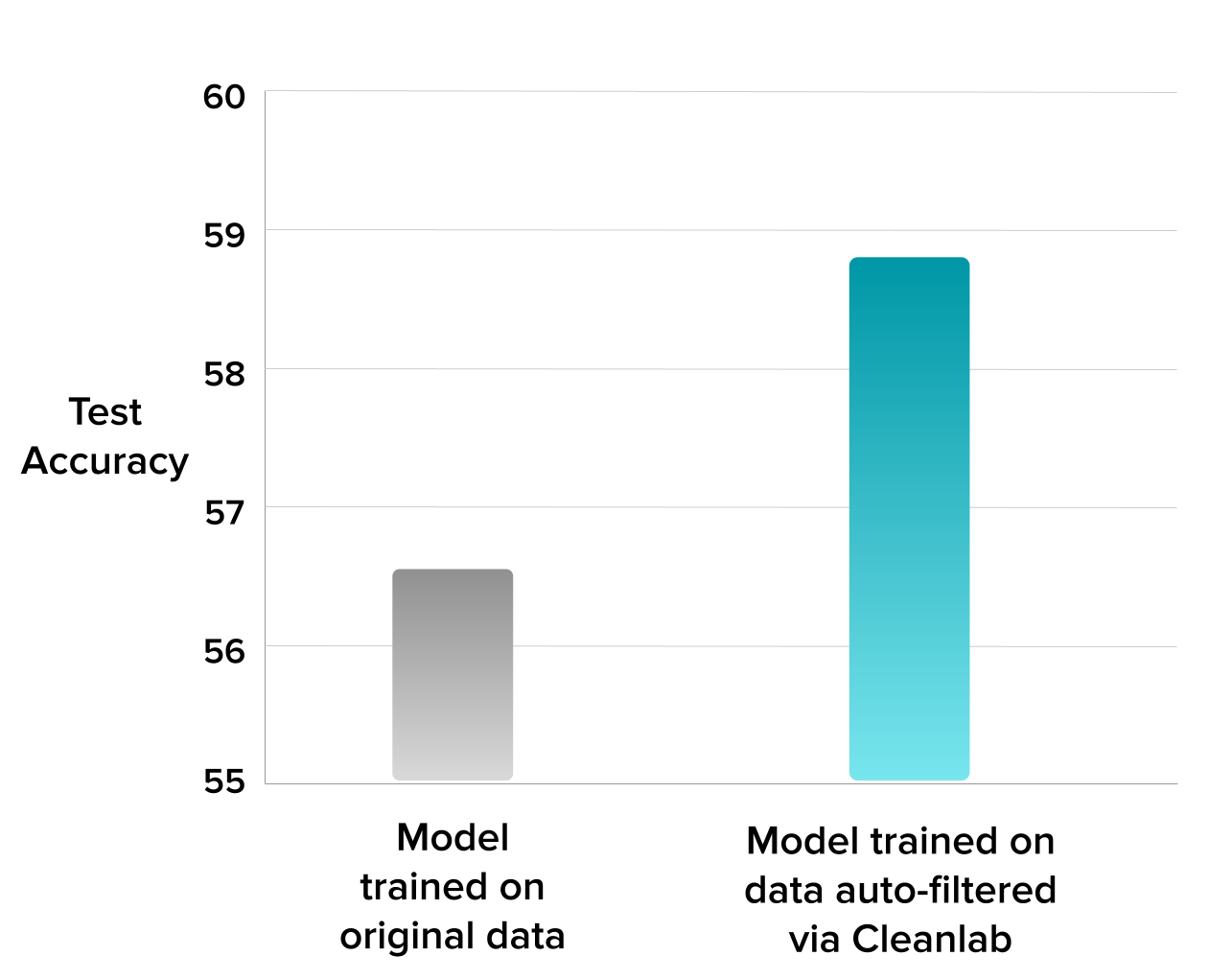
For this dataset, Cleanlab Studio’s AutoML automatically produced a more accurate visual concept classification model (56.7% accuracy) than ShareChat’s in-house 3D ResNet model (52.6% accuracy). Auto-correcting the dataset immediately boosted Cleanlab AutoML accuracy up to 58.9% (see chart).
ShareChat is India’s largest native social media app with over 300 million users. The company employs large teams of content moderators to categorize user video content in many ways.