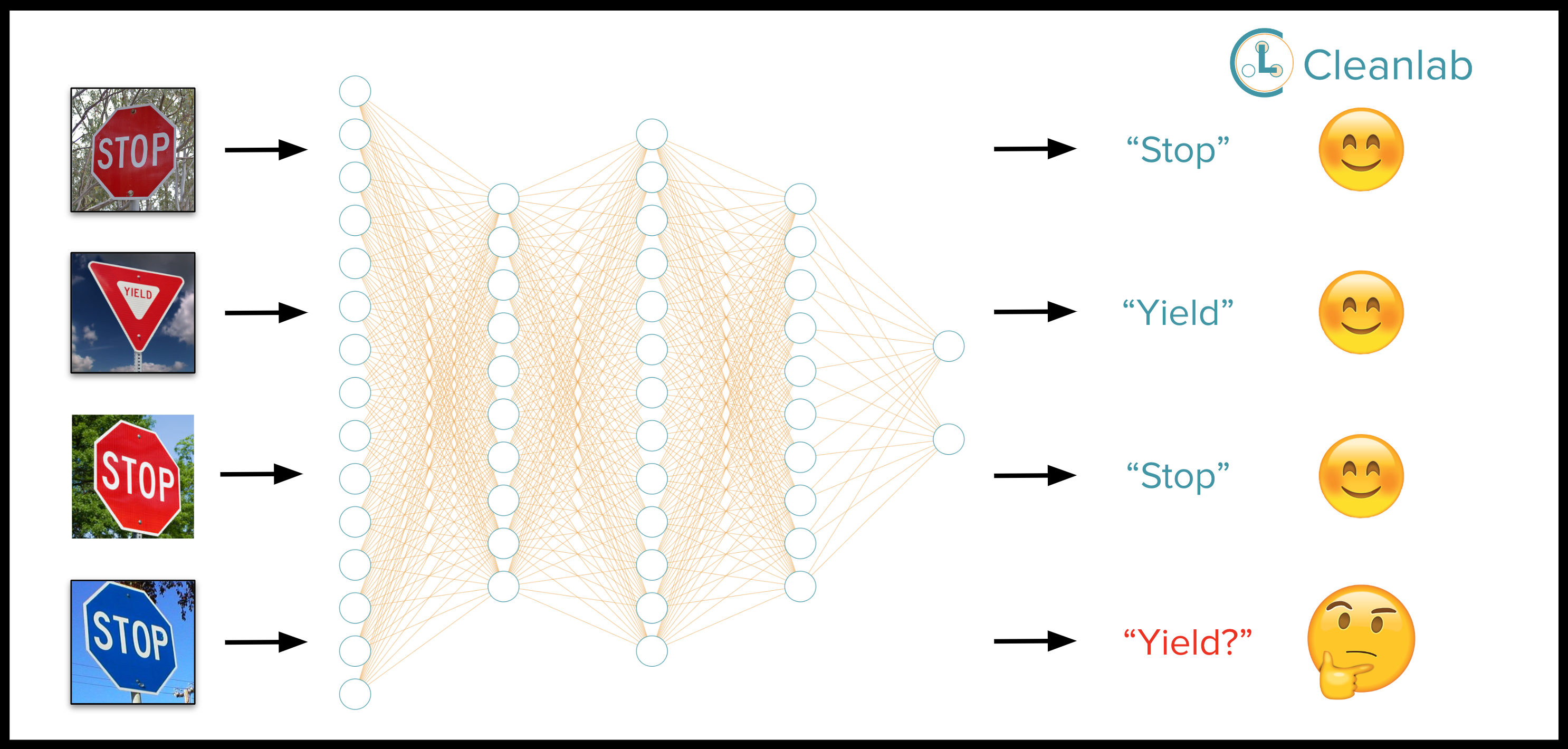
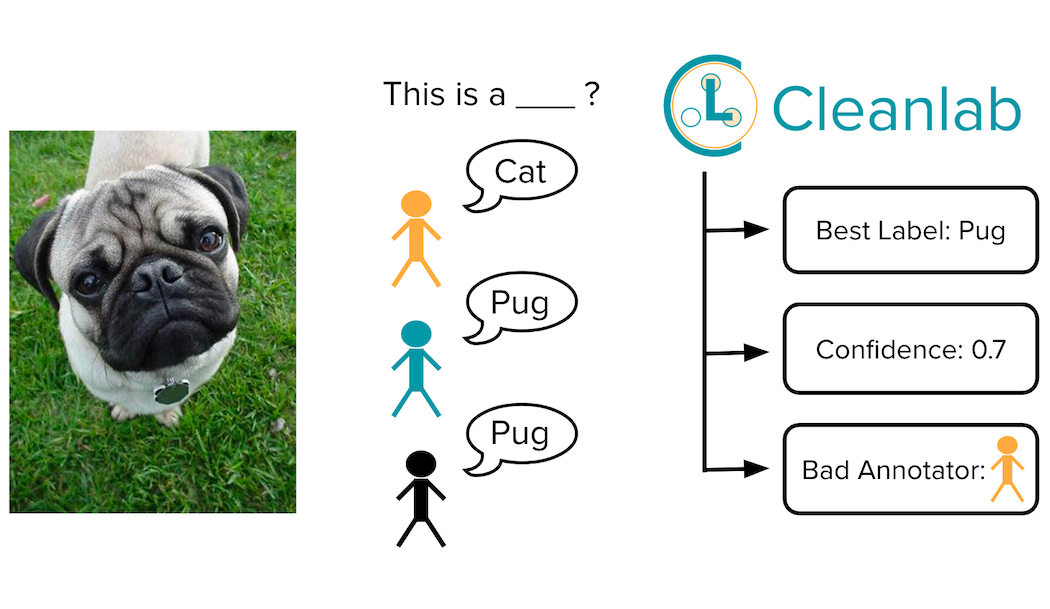
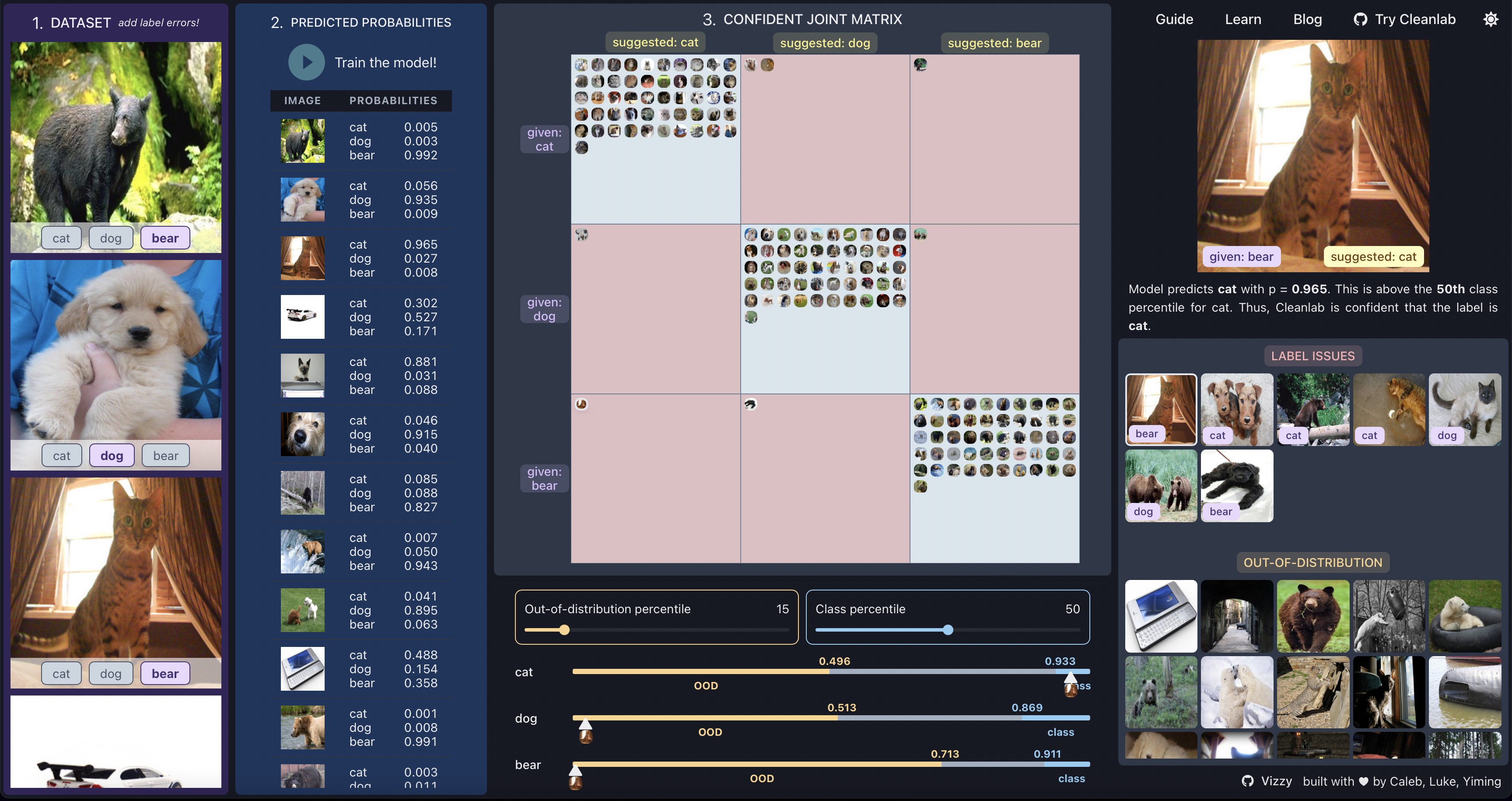
Blog
Company updates, tutorials, research, and more!
All
New Research
New Feature
Open Source
Cleanlab Studio
Tutorial
Company News
Generative AI
Educational
Select Tag
New Research
New Feature
Open Source
Cleanlab Studio
Tutorial
Company News
Generative AI
Educational
Select Author
Vedang Lad
Jonas Mueller
Chris Mauck
Ulyana Tkachenko
Curtis Northcutt
Elías Snorrason
Aditya Thyagarajan
Mayank Kumar
Hui Wen Goh
Hang Zhou
Anish Athalye
Angela Liu
Sanjana Garg
Jesse Cummings
Yiming Chen
Wei-Chen (Eric) Wang
Caleb Chiam
Luke Mainwaring
Wei Jing Lok
Johnson Kuan